Videos: Course in Multi-threaded Programming, Tuning and Optimization
CSCS organised a 2 and half-day intensive course focused on multi-threaded programming, tuning and optimization and multi-threaded libraries on massively parallel processing (MPP) systems that are composed of multi-core processors.
We would like to share with you the videos of the different classes.
Here you can access all the videos »
Or select the unit you are interested in:
Performance considerations, best practices and misconceptions

1. Hybrid MPI and OpenMP programming – 2. Hierarchical MPP systems – 3. Xeon based cluster – 4. Threading (OpenMP) and Multi-cores – 5. Micro-processor optimization and OpenMP scaling – 6. Compiler optimization – 7. Mapping and control of tasks and threads – 8. Hyper-threading on Xeon – 9. Performance measurement and analysis – 10. Myths and realities – 11. Future of MPI and OpenMP
Using perftools for threaded and hybrid codes

1. Craypat basics – 2. Craypat automatic performance analysis – 3. Craypat analysis: a slightly different approach – 4. Detecting load imbalance – 5. Apprentice2 basics
Debugging Tools

1. Potential errors in multithreaded codes: 1.1 Data race condition – 1.2 Deadlocks – 1.3 Livelock – 1.4 Memory issues – 2. Debugging: 2.1 Important debugging concepts – 2.2 Debugging considerations unique to OpenMP – 2.3 Debugging tools available on CSCS platforms
Debugging of parallel programs with TotalView

How to use TotalView to debug parallel programs.
The Cray Programming Environment

1. Programming environment overview: 1.1 Modules – 2. Compilers: 2.1 PGI, Cray, GNU, Intel, Pathscale – 3. Programming considerations – 4. MPI communications – 5. Running an application
OpenMP Parellisation Strategies

1. Examples of pure OpenMP – 2. The basics of running a parallel OPenMP job – 3. Parallel regions and shared or private data – 4. Fine-grained loop-level work sharing – 5. Architecture of a multi-core multi-socket node – 6. NUMA – Non-Uniform Memory Access – 7. Caches hierarchies and locality – 8. Cache coherence (amongst multiple cores) – 9. Super-scalar out-of-order pipelines with SIMD – 10. Operating system memory allocation – affinity – 11. Memory affinity bandwidth change – 12. Communication mechanism for message passing – 13. Process Memory Model – 14. Halo regions and replicated data in MPI – 15. Domain decomposition on a 2D grid – 16. Stop-start mechanisms in MPI – 17. Asynchronous implementations in MPI libraries – 18. Contention – Cache trashing, false sharing – 19. Thread creation overhead and synchronization – 20. User-level thinking with distributed and shared memory
MPI and OpenMP Hybrid Parallelism for Multi-core Processors

Introduction to parallel and multi-threaded programming: 1. Programming models for parallelism – 2. Historical usage of MPI/OpenMP – 3. The need for MPI on distributed memory clusters – 4. Simple cases where MPI/OpenMP might help – 5. What MPI provides – 6. Alternatives to OPenMP – 7. PThreads – 8. Quick note on GPU accelerator programming – 9. The 4 options for thread support – 10. Hybrid programming on Cray systems
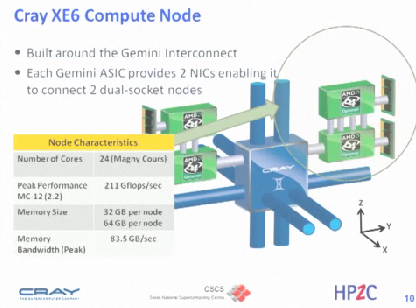
The Cray XE6 Architecture

1. Cray MPP product line – 2. Cray XE architecture: 2.1 Cray XE6 node – 2.2 Cray XE6 configurations, topology – 3. Cray XE6 scalable software: 3.1 Service and compute nodes – 3.2 CNL, Lustre, MPI – 4. Cray XE6 configuration: 4.1 Cray XE6 blades, cages, cabinets – 5. Application launching process
Introductory Course on OpenMP Programming

1. Basic information: 1.1 Introduction to programming model – 1.2 Directives for work parallelization and synchronization — 2. Hands-on Lab: 2.1 Writing compiling and executing simple OpenMP programs – 2.2 Identifying and resolving common issues — 3. Advanced topics: 3.1 Constructs introduced in OpenMP 3.0 — 4. Hands-on Lab: 4.1 Examples with OpenMP3.9 directives